はじめに
個人的にtarget trial emulationについて勉強する機会があったので備忘録としてもまとめたいと思います。
目次
target trial emulationとは?
横文字は嫌いですが、残念ながら、適切な日本語訳が今のところ存在していない(と思っています)ので、このままtarget trial emulationを使っていきます。
最近激アツのhot topicです。頭痛が痛いみたいですね。
ここ数年で論文投稿数が鰻のぼりに上昇しています。

前提知識
前提知識として、過去記事でも解説した通り、RCTは選択バイアスを減らせる良いデザインです。 syleir.hatenablog.com また、そのほかの想定していない交絡因子も調整してくれる優れものです。実際にRCTと観察研究が結果が食い違っている研究がいくつかありますが、多くの場合はRCTの方がバイアスを低減することができるデザインとされ、信頼性が高く、意思決定に用いられることが多いです。 一方で、RCTには多くの制約があります。- ①倫理的制約
- ②時間的制約
- ③金銭的制約
歴史的な流れ
歴史的な流れは理解には不要です。興味がある方だけ読んでください。 これは論文を読んでいる中で当たったもので、成書を当たったわけではないですし、ざっとしか読んでいないので正しさは保証できませんが、大枠の時系列を説明します。 target trial emulationはHarvardのHernánによって発展させられてきた概念です。最初の概念自体はEpidemiology. 2011 May;22(3):290-1.にあり、大規模データベースを用いた観察研究でもRCTと同じような枠組みで考え、CONSORTチェックリスト(RCTの結果を報告するためのチェックリスト)の枠組みで、観察研究でも同じように確認し、どのようにemulateしたか(この論文で実際にemulateという単語が出てきます)を報告する推奨が出されました。これがtarget trial emulationの概念の始まりと思われます。 実際の枠組み、方法論に関しては同じくHernánがAm J Epidemiol. 2016 Apr 15; 183(8): 758–764.の報告で、具体的な「マネ」の仕方を提示してくれました。 教科書では2020年にWhat ifが出版され、この中で取り上げられています。2024年7月に新版が出るようです。 そして、2022年にHernánがJAMA. 2022 Dec 27;328(24):2446-2447.にGuide to Statistics and Methodsとして方法論のガイドとしてのeditorialをCOVID-19に対するトシリズマブでの治療を例に、記載してくれたのでした。そしてJAMAにも載ったことで、一躍価値が認められ、前述したような爆発的な論文数の増加につながっていったのでした。target trial emulationの手順
以下、具体的な原著でいうframework:枠組みを解説していきます。target trial emulationは2ステップからなる
target trial emulationは以下の2ステップで構成されます。①どのような因果関係が知りたいのかを明確にしてそれを明らかにする仮想RCTをデザインする
第1段階は、どのような因果関係が知りたいのか?を明確にし、それがたとえ非現実的であろうと、RCTの形で定義します。現実的にはRCTが何らかの理由でできないにしろ、その制約がなかったと考えて、(例えば金銭的制約があるのであれば無限のお金があると仮定し、)「仮想RCT」を想定します。 実際に、RCTをやるなら、どのような患者を組み入れるのか、どのような治療を、どのような薬の量、期間で、どのように割り当てを行い、アウトカムをどのように設定し、どのように追跡し、どれくらいの期間追跡するか、どのように解析するかなどをできるだけ詳細に定義します。
②実際に観察データを利用して仮想RCTを模倣する
第2段階は、観察データを使用し「仮想RCT」の手順を模倣します。 上で定義した手順通りにデータベースから適格なデータを見つけ、割り当てを行い、治療を行ったとして、アウトカムが生じる、あるいは実験終了までを追跡し、同じ解析を実施します。しかし、観察研究であり、ランダムな割り付けはできないため、割り当てだけは傾向スコアマッチングなどを利用して擬似的な割り当てを行います。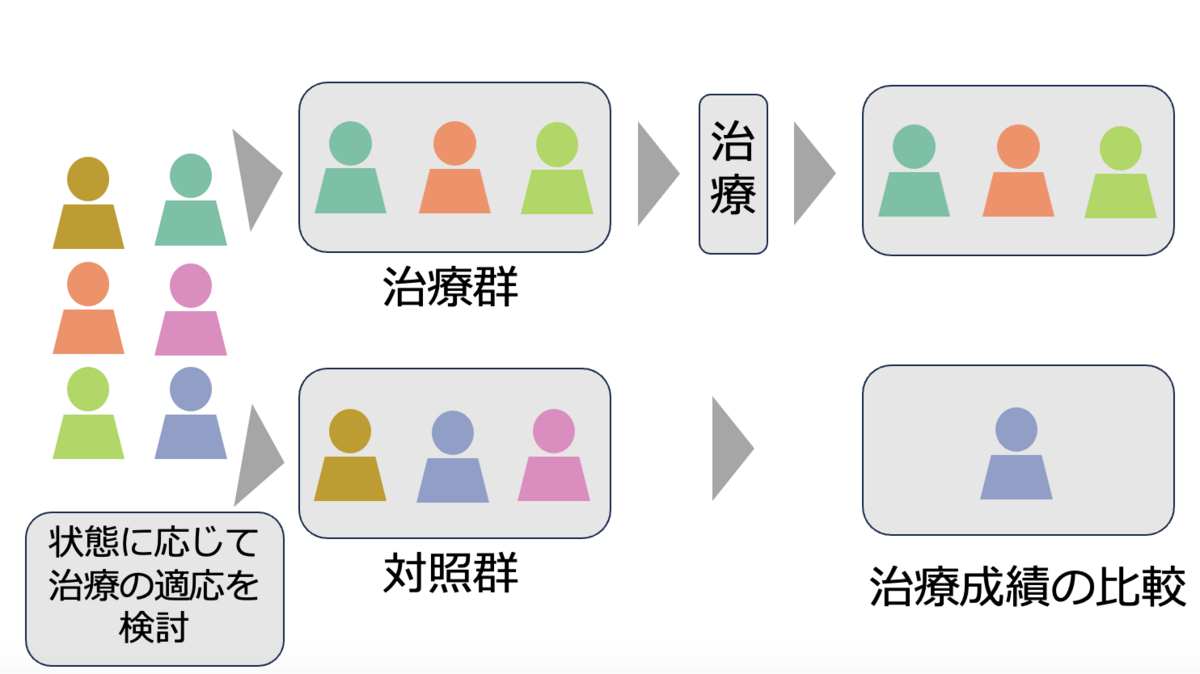


")



















")