はじめに
今回の連続記事は傾向スコアマッチングにおいて、Pythonでの最適ペアマッチングの実装がインターネット上になかなか落ちていなかったので解説しようという試みです。これを読むことでPythonでの最適ペアマッチングの実装がわかります(需要ある?)
最初からアルゴリズムを載せても何がなんだかという感じだと思うので二部構成にして最初はとっつきやすい感じにしてあります。
統計的因果推論において、マッチングを利用することでバイアスを減らそうと計画することがあります。
RCTが行えないような観察研究において、アウトカムに影響を与えるような交絡因子が近い組をマッチングすることで、原因が結果に及ぼす因果関係をより明確にする意図があります。
マッチングにおいては、色々なマッチング方法があります。たとえば、ランダムフォレストやベイズ的な手法、これから紹介する傾向スコアマッチングなどがあります。
目次
傾向スコアマッチングとは?
ランダム化は観測された共変量及び、観測されない共変量のバランスを取ることで因果関係を示すことができるという意味で他の研究デザインよりも優位性があると過去記事で書きました。詳しくはこの記事をご参照ください。
syleir.hatenablog.com
ランダム化比較試験(RCT)は素晴らしい研究デザインですが、様々な制約によりRCTができないことがあります。
そのような際に傾向スコアによるマッチングを用い、観測される共変量のバランスを取り、交絡による影響を減らすことでよりRCTに近づけた状態でバイアスの影響を減らすデザインを取ります。
ざっくり言うと、傾向スコアは観測されている共変量から計算される処置群への割り当てられる確率なので、これが似た値のペアを対照群と処置群で作ることで、共変量の影響を減らすということです。
傾向スコアマッチングの種類
傾向スコアマッチングにはマッチング方法が複数あります。
RではMatchItなどのライブラリを用いてマッチングを行う方法が最もよく使われると思います。
具体的に列挙すると
- 最近隣法マッチング(nearest neighbor matching)
- 最適ペアマッチング(optimal pair matching)
- 遺伝的マッチング(genetic matching)
- 厳密マッチング(exact matching)
- 単純化厳密マッチング(coarsened exact matching)
- 層化(subclassification)
- 最適フルマッチング(optimal full matching)
などがあります。
最適ペアマッチングとは?
最近隣法マッチングとの対比がわかりやすいので比べながら説明していきましょう。
まず、最近隣法マッチングについて解説します。
最近隣法マッチングは、以下の手順で行います。
①それぞれの群を小さい順(または大きい順)に並び替え(ソート)をします。
②サイズの小さい群から順番に個体を選択し、もう一方の群から「距離」が最も近いものを抽出してマッチングさせます。
たとえば以下のような傾向スコア(propensity score:PS)を持つ2群を考えます。ここでは「距離」については単純にPSの絶対値の差と考えます。
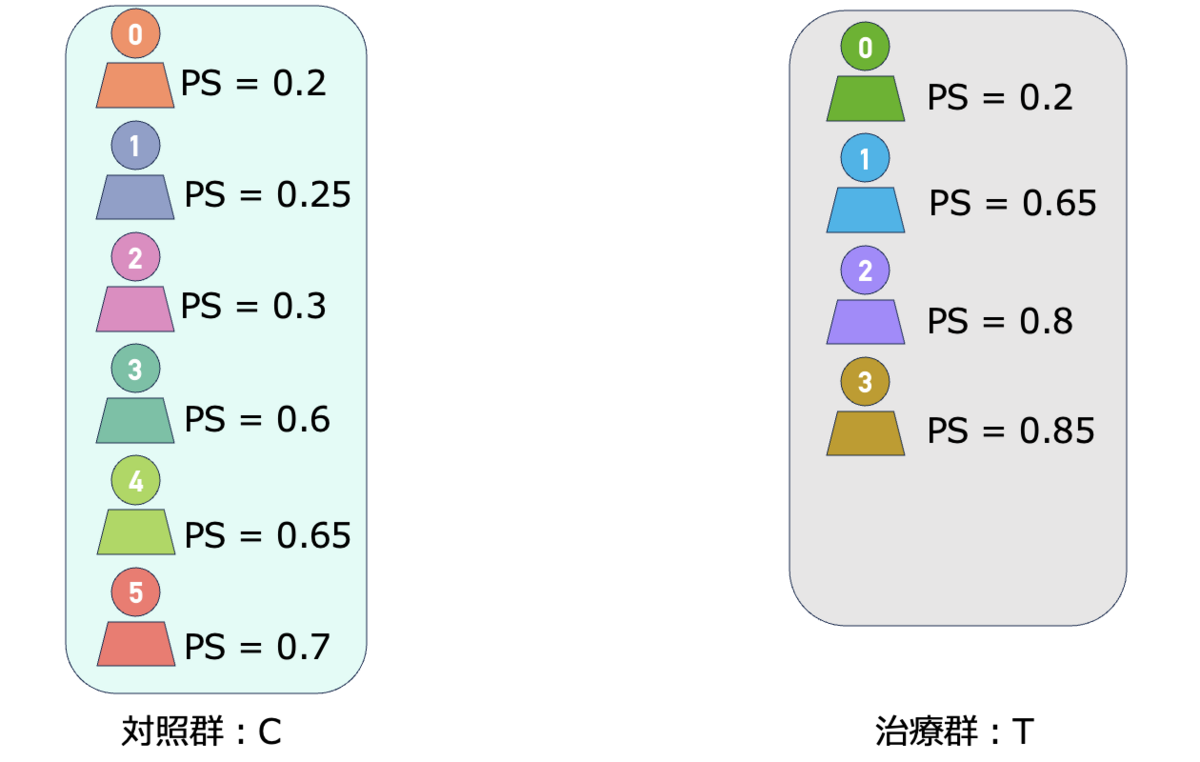
図が煩雑なので、このようなマッチング理論ではグラフ理論を利用し単純なグラフで書くことがあります。下記のようにノード(丸)とエッジ(線)で単純化します。

右側の0番の個体から傾向スコアが近い順で順番にマッチングさせていくと以下のようになります。

非復元抽出と復元抽出
さて、このマッチングは本当に「良い」マッチングと言えるでしょうか。
直感的には右の群の3番と左の群の3番がマッチングしているのが気持ち悪いような気がします。
マッチングの基本理念は「交絡因子が近い組をマッチングすることで、原因が結果に及ぼす因果関係をより明確にする」ことでしたから、PSが大きく違う個体同士のマッチングは「良いマッチング」とはなりません。
これを解決するのが復元抽出によるマッチングです。
復元抽出は同じノードの2回以上の使用を許すことです。復元抽出を許して上のように最近隣法マッチングを行うと以下のようになります。

このように、左の群の5番が2回使われることでより良いマッチングになっていることがわかります。PSが0.25違うところから0.15の差まで減らせていることがわかります。
最適マッチング
復元抽出による最近隣法マッチングは万能でしょうか?
復元抽出を行うことで、使用しているデータが減る(情報量が減る)、同じデータを複数使うことでアウトカムが偏るなどの欠点があります。
データの分布次第では同じ個体がかなりの多くの回数マッチングさせられて結果自体が歪んでしまうことだって考えられます。
そのような際に使うのが最適ペアマッチング(Optimal Pair Matching)です。
最適マッチングの方法
最適マッチングは全ての組み合わせの中からPSの差の合計が最も小さくなるように選びます。
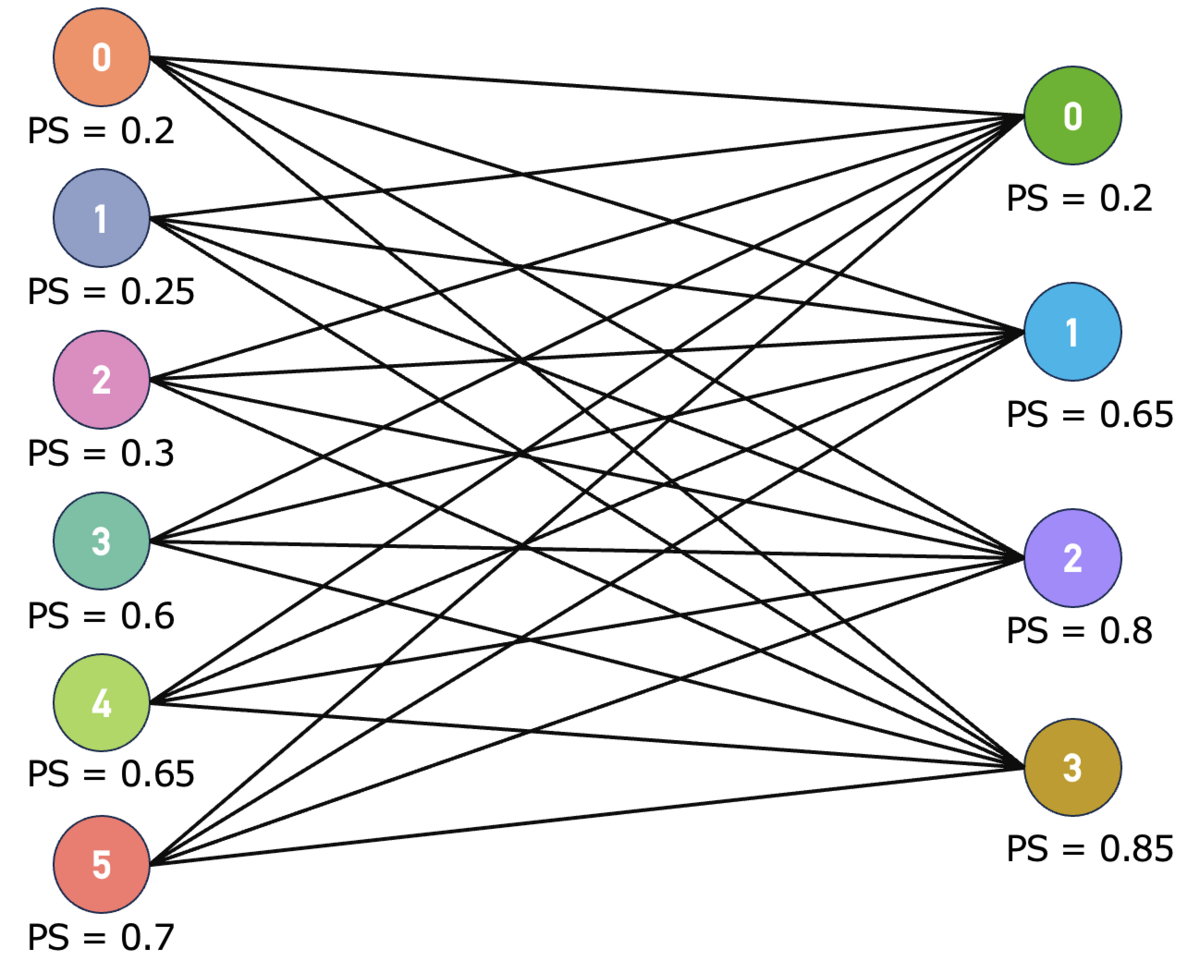
このように全ての組み合わせを考え、その中で最もPSの差の合計が最も小さくなるように選ぶと以下のようになります。

先ほどよりも「良い」マッチングになりつつも最大限の情報量を活用していることがわかります。
難点はコンピューターの計算量が増えること、実装が難しいことです。データの数が増えれば増えるほど計算量が増え、また最近隣法を選択した時のデータの偏りも減るので、一般的にはデータ数が少ないマッチングの際に使われます。
どのように実装、アルゴリズムを考慮するかは次章で解説します。
References
2023年1月に出た、傾向スコアにのみ重点的に触れた貴重な本です。基本的なところから解説してくれていてかなり読みやすいです。")
今シーズンのベストバイだと思っています。Rでの実装を載せながらかなり詳細に解説してくれています。

サンプルデータもありますし、Rが使えるのであれば相当おすすめです。
Part2はこちら
次回実装編です。Pythonを用いて最適ペアマッチングを実装していきます。
syleir.hatenablog.com