はじめに
前章では最適ペアマッチングの利点、活用方法について解説しました。
そこで今回は実際の考え方・実装を解説します。
目次
二部グラフマッチング
今回の最適ペアマッチングは二部マッチングという概念に包含されます。
二部マッチングは2つの異なる集合から成るグラフ(二部グラフ)において、辺を選んで、それぞれの頂点が高々1つの辺に関連付けられるような集合の組み合わせを見つける問題を指します。
より平たく言うと、2つの集合から重複がないようにペアを作っていく問題です。
実社会でもよく使われています。
例えば、
- 男性の集合、女性の集合から重複がないようにペアを作るマッチングアプリ
- 会社の集合、就活生の集合から重複がないようにペアを作る就職のマッチング
- 工場の集合、リソース(人間や原材料)の集合から重複がないようにペアを作るリソースの割り当て
などがあるでしょうか。
最小重み最大二部マッチング
そして今回の最適ペアマッチングを求める問題は二部マッチングの問題の中でも最小重み最大マッチングという問題に帰結されます。
最小重みマッチングは、二部グラフ内の辺に非負の重み(コストやコストと見なされる値)が割り当てられた場合に、それらの辺を選んでマッチングを形成する際の最小総重みをとるマッチングを求める問題です。
最小重みマッチングの場合は「選ばない」という選択肢が全ての辺の選択の中で自明に一番コストが低く、ナンセンスな問題になってしまいますから、最大マッチング(=できるだけ多くの辺を選ぶ)という制約を追加します。
つまり、最小重み最大二部マッチングは、「辺に重みが与えられている二部グラフにおいて、頂点の重複がないようにできるだけ多くの辺を選び、その選んだ辺のコストを最小化する」というような問題になります。
具体的な例を挙げましょう。

このような二部グラフに対して辺に重みが与えられているものを考えます。
最小重み最大マッチングとして選ばれるのは
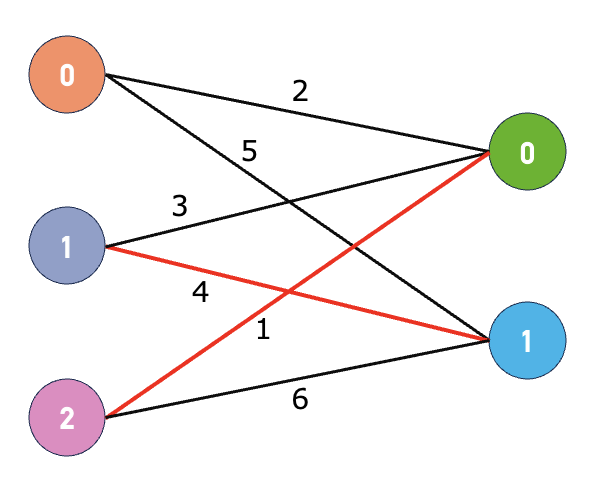
このように 1 - 1 , 2 - 0 の合計重み5の組み合わせになります。
これを解くアルゴリズムは最小費用流を用いた方法や、Hungarian法などがあり解くことができます。
ということで、最適ペアマッチングをこれに帰着すれば良いことがわかりました。
最適ペアマッチングを最小重み最大二部マッチングに帰着する
さて、前章で用いた例を使います。
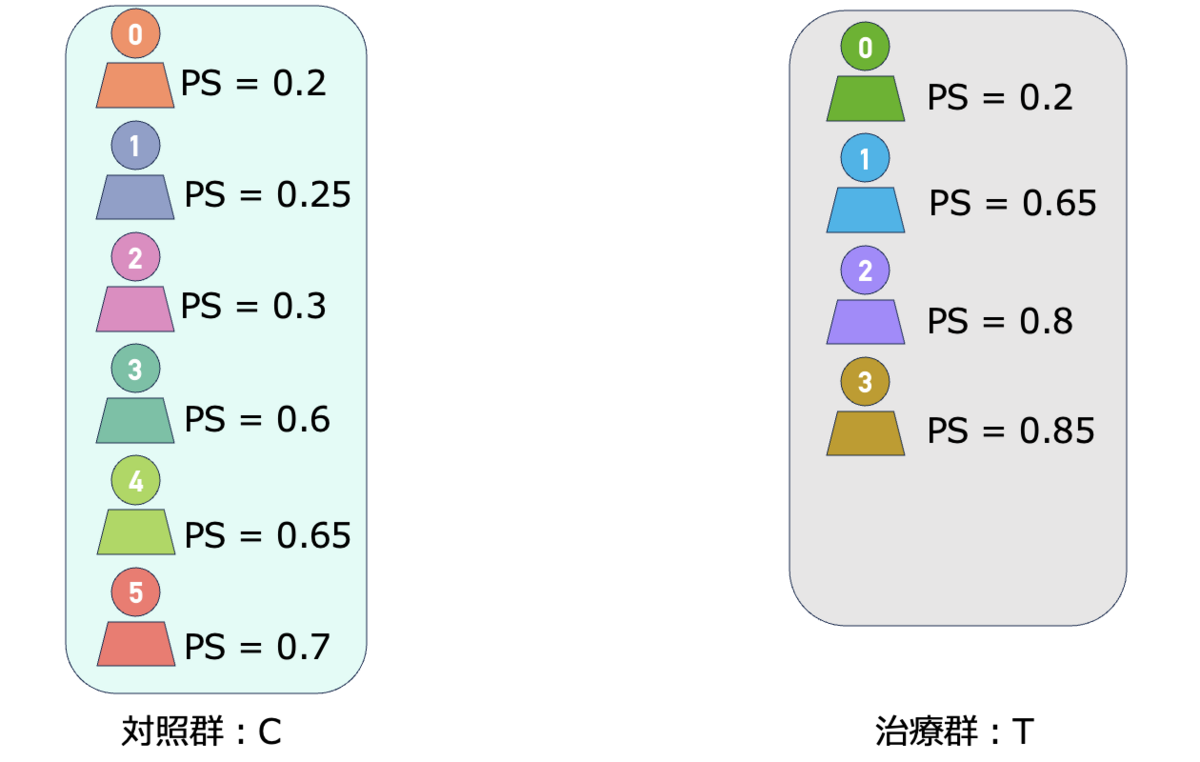
このような対照群:6人、治療群:4人に対して、傾向スコアを計算し与えられている例を考えていました。
これをグラフ理論的に頂点と辺に直すとこのようになるのでした。
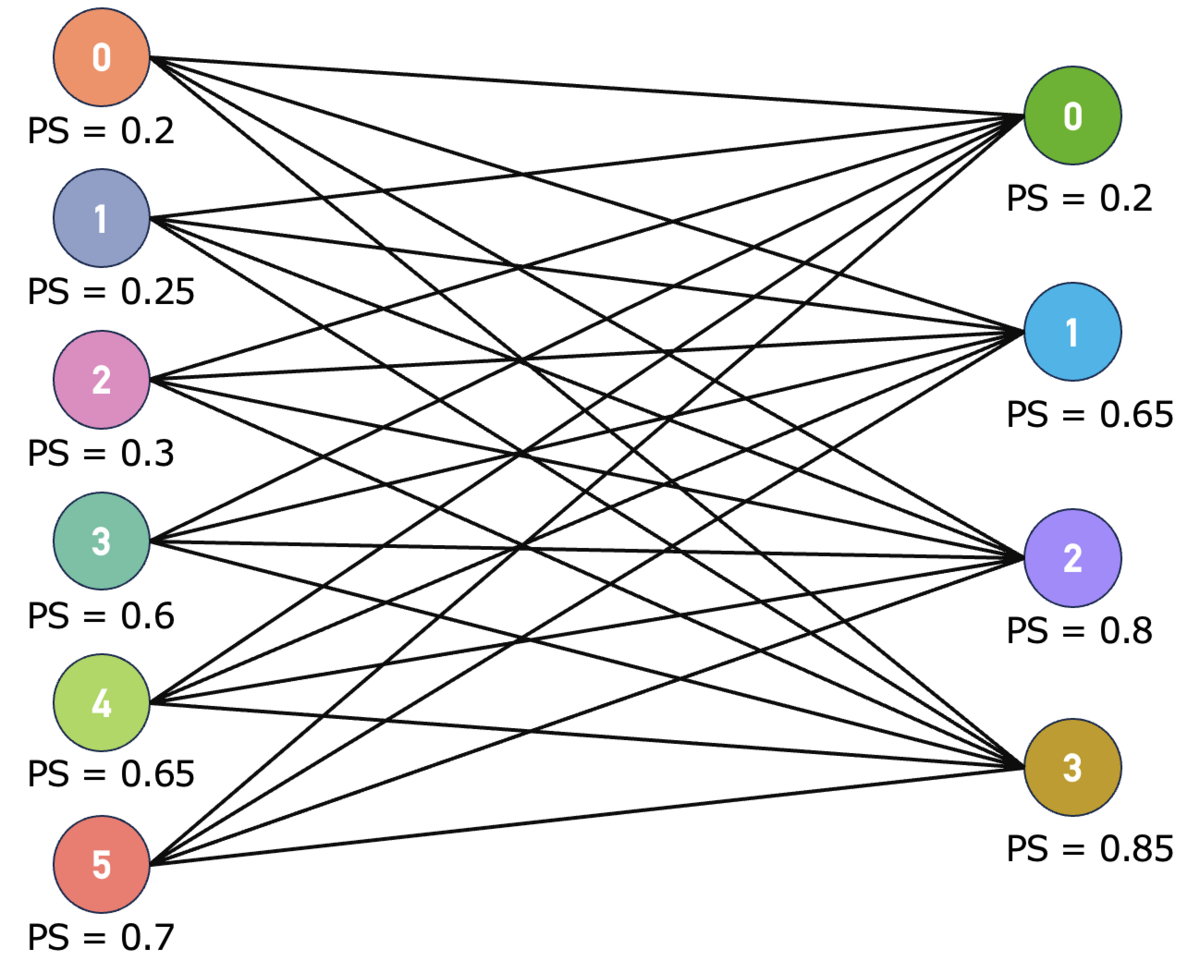
今は頂点それぞれがPSの情報を持っているわけですが、最小重み最大二部マッチング問題は辺に非負の重み(コストやコストと見なされる値)が割り当てられていることが必要になるわけです。
最適マッチングの目指すところは、「全ての頂点の組み合わせの中からPSの差の合計が最も小さくなるように頂点のペアを選ぶ」ことでしたから、これを
「全ての頂点の組み合わせから頂点のペアを選ぶ」→「頂点が被らないように辺を選ぶ」
「頂点のPSの差」→「辺のコスト:その辺が結ぶ頂点同士のPSの差の絶対値」
と言い換えてあげることにより、
「全ての頂点の組み合わせの中からPSの差の合計が最も小さくなるように頂点のペアを選ぶ」
→「できるだけ多くの辺を選ぶマッチングのうち、コスト(=PSの差の絶対値)の合計が最も小さくなるように辺を選ぶ」
と適切に言い換えることができますから、これで最適ペアマッチングを最小重み最大二部マッチングに帰着することができました。
つまり、

このように辺に重みを与えて辺を選ぶ問題と帰着することで最小重み最大マッチング問題に帰着することができるのです。
最小重み最大二部マッチング問題を解く
これを解くアルゴリズムは最小費用流を用いた方法や、Hungarian法などがあります。
二部グラフのマッチング問題は競技プログラミングの文脈でも頻出です。下記を参照ください。
qiita.com
しかし、Pythonの便利なところはなんでしたか?そう、豊富なライブラリによって実装力がなくてもライブラリで殴ることができることです。
今回はNetworkXというライブラリを使いましょう。
NetworkXとは?
NetworkXは、Pythonでグラフを作成、操作、可視化するためのライブラリです。
余談ですが、AtCoderでも使用可能です。ライブラリの読み込みが遅く、ナイーブな実装に処理速度で負けるためあまり使われていません。
今回は処理速度は問わないので便利なものは使っていきましょう。
実装
#ライブラリの読み込み from scipy.spatial.distance import cdist import numpy as np import networkx as nx
ライブラリを読み込みます。今回、networkxの他に辺のコストを効率よく求めるためのライブラリとしてscipyと行列はnp.arrayとして持つ必要があるのでnumpyを使います。
# コントロール群と処置群の傾向スコアがそれぞれ与えられていると仮定 control_scores = np.array([0.2, 0.25, 0.3, 0.6, 0.65, 0.7]) treatment_scores = np.array([0.2, 0.65, 0.8, 0.85])
上で使った例と同じ数字を使っています。同じ結果が出るかを確かめましょう。
# コントロール群と処置群の傾向スコア間の距離行列を計算 distance_matrix = cdist(control_scores.reshape(-1, 1), treatment_scores.reshape(-1, 1))
ここで、distance_matrix は以下のようになっています。

これは上のグラフで求めた辺のコスト(=PSの差の絶対値)に対応しています。
わかりやすくするとこうです。

これでdistance_matrixに辺のコストの情報を持たせることができました。
#グラフを作る前に各群のサイズを求めておく control_size = len(control_scores) treatment_size = len(treatment_scores)
#グラフを作る graph = nx.Graph() #距離行列の値を重みとしてグラフにエッジを追加 for i in range(control_size): for j in range(treatment_size): graph.add_edge(f"C{i}", f"T{j}", weight=distance_matrix[i, j])
# 最小重み完全マッチングを求める
matching = nx.min_weight_matching(graph)
NetworkXではグラフを用意してあげれば、min_weight_matchingで最小重みマッチングを作ってくれます。最強ですね。
# マッチング結果を表示 print(matching)
>>出力:{('C5', 'T3'), ('T0', 'C0'), ('T1', 'C3'), ('C4', 'T2')}
となり、正しい出力が得られていることがわかります。とは言ってもややわかりにくいのでいい感じに可視化をします。
可視化
import matplotlib.pyplot as plt # コントロール群と処置群のノードを指定 control_nodes = ['C0', 'C1', 'C2', 'C3', 'C4', 'C5'] treatment_nodes = ['T0', 'T1', 'T2', 'T3'] # 二部グラフを作成 G = nx.Graph() # ノードを追加(二部グラフにおけるノードの属性を指定) G.add_nodes_from(control_nodes, bipartite=0) # bipartite=0 はコントロール群を示す G.add_nodes_from(treatment_nodes, bipartite=1) # bipartite=1 は処置群を示す # マッチングをエッジとして追加 G.add_edges_from(matching) # 二部グラフのレイアウトを取得(ノードを正順に配置) layout = {node: (1, i) for i, node in enumerate(reversed(control_nodes))} layout.update({node: (2, i) for i, node in enumerate(reversed(treatment_nodes))}) # 二部グラフを描画 nx.draw_networkx_nodes(G, pos=layout, nodelist=control_nodes, node_color='b', node_size=500, alpha=0.8) nx.draw_networkx_nodes(G, pos=layout, nodelist=treatment_nodes, node_color='g', node_size=500, alpha=0.8) nx.draw_networkx_edges(G, pos=layout, edgelist=matching, width=2, alpha=0.5, edge_color='r') # ノードのラベルを描画 node_labels = {node: node for node in G.nodes} nx.draw_networkx_labels(G, pos=layout, labels=node_labels) plt.title("Optimized Matching Result") plt.show()
図示だけなので細かいテクニックは省略します。
結果は以下のようになります。
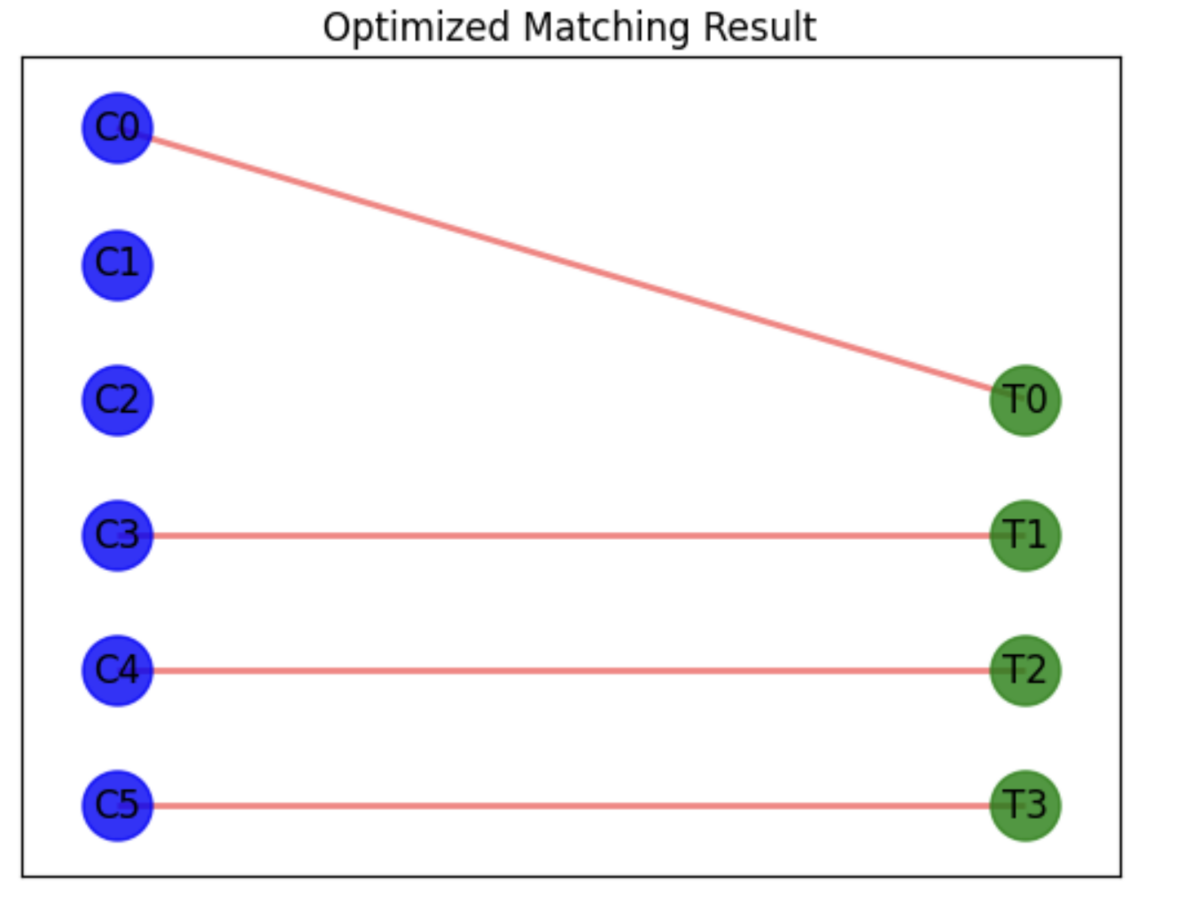
当初の結果と比較しても正しい結果が得られていることがわかります。

おわりに
いかがでしたか?
いつか解説記事のおわりにいかがでしたか?を書いてみたいと思っていました。
ややニッチな内容でしたが、理解の助けになれば幸いです。
references
NetworkXについて興味を持った方、より詳しい実装についてはこちらがおすすめです。

洋書ですが、因果推論のPythonでの実装について触れている本です。いつか和訳になるんでしょうか。ならない気がします。
